A personal reflection on why I insisted on an Enterprise IoT Platform with on-premise deployment
There are moments in a founder’s life when you stop talking about features.
You stop talking about dashboards.
You stop talking about protocols.
You even stop talking about scale.
And you start talking about control.
This was one of those moments.
I remember sitting quietly after one of our internal briefings, staring at the whiteboard filled with arrows, boxes, and deployment diagrams. Everyone had left the room. The air was still.
Why am I pushing so hard for this Enterprise Plan?
Why does this feel heavier than just another pricing tier or feature release?
Then it hit me.
This was not about software.
This was about sovereignty.
And once you see it that way, you can never unsee it.
From owning a kitchen to owning the whole restaurant
For years, I used a simple analogy when explaining IoT platforms.
If you are on a shared cloud platform, you are like a chef renting a kitchen. You can cook. You can serve. But you do not own the space. You follow house rules. You live with limits.
The Enterprise Plan is different.
It is not about owning the kitchen anymore.
It is about owning the whole restaurant.
The building.
The keys.
The doors.
The data flows.
The servers are sitting quietly in your own premises.
When you own the restaurant, no one tells you when to close. No one caps how many customers you can serve. No one decides where your ingredients come from.
That is the mindset behind the Enterprise IoT Platform.
The moment I realised cloud is not always the answer
For a long time, cloud felt like the default answer to everything.
Fast.
Flexible.
Convenient.
I believed in it. I still do, for the right use cases.
But over the years, as I spoke to large organisations, city operators, government agencies, and critical infrastructure owners, a pattern kept repeating itself.
“We don’t want our data outside the country.”
“We need to know exactly where the servers are.”
“We cannot afford external dependencies for this system.”
“This data is too sensitive.”
At first, some people dismissed these concerns as paranoia.
I did not.
Because when you are dealing with traffic lights, water systems, energy grids, and public safety sensors, paranoia is just another word for responsibility.
What happens if the platform is outside the country and something goes wrong?
Who takes control when connectivity is lost?
Who answers when an entire city goes dark?
These are not theoretical questions. These are operational nightmares waiting to happen.
Data sovereignty is not a buzzword when infrastructure is involved
Data sovereignty sounds abstract until you put real consequences next to it.
Imagine a critical infrastructure monitoring system managed by a platform hosted overseas. One day, there is a major failure.
Power outage.
Network disruption.
Access blocked.
The local operators are standing there, staring at blank screens, unable to take control because the system that runs their infrastructure is not physically within reach.
That is unacceptable.
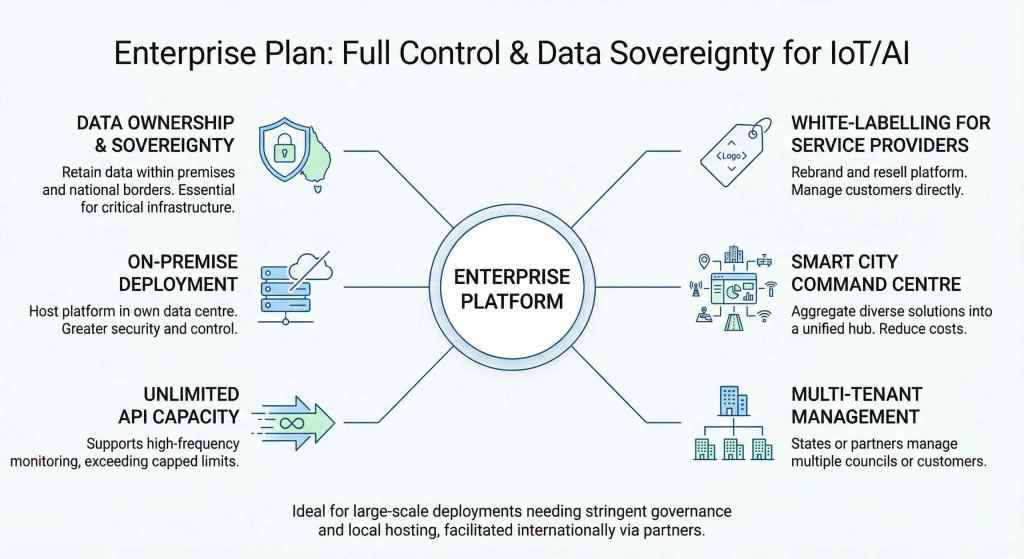
This is why on-premise deployment matters.
Not because it sounds serious.
Not because it looks impressive in a proposal.
But because control must stay with those who are accountable.
This thinking shaped every part of the Enterprise IoT Platform plan.
AI made the stakes even higher
If IoT data is sensitive, AI makes it explosive.
AI models learn from data.
Patterns.
Behaviours.
Weak points.
When AI touches critical infrastructure data, the question is no longer just “where is my data?”
It becomes “who understands my system better than I do?”
That was the turning point for me.
If AI is going to sit on top of IoT data, then the data must never leave the country.
This is not about fear.
This is about governance.
Every country I speak to says the same thing, whether it is Malaysia, Indonesia, the Middle East, or Europe.
“We want AI. But we want our data at home.”
The Enterprise Plan was designed to respect that reality.
Unlimited API is not a luxury; it is a survival
One detail that often gets overlooked is API limits.
People ask me, “Why unlimited API? Isn’t that excessive?”
Let me paint you a picture.
A manufacturing line monitors machines every second.
One sensor. One data point per second.
Multiply that by hundreds of machines.
Multiply again by shifts, days, months.
Suddenly, 500,000 API calls per day is not generous. It is restrictive.
The Developer Plan has limits because it should. It is built for builders, experimentation, and controlled scaling.
But enterprise environments do not experiment. They operate.
If you throttle data in an industrial environment, you are not saving costs. You are introducing blind spots.
Unlimited API is not about indulgence.
It is about continuous visibility.
Two very different enterprise realities
As I refined this plan, two clear deployment models kept emerging.
1. The white-label service provider model
Some organisations do not want to sell hardware.
They want to sell managed IoT services.
They do not want to build a platform from scratch. That path is expensive, slow, and painful.
So they white-label the Enterprise IoT Platform.
Their brand.
Their customers.
Their business logic.
They plug in their agricultural sensors, industrial devices, and vertical solutions, and run everything on their own enterprise platform.
Thousands of customers.
One controlled system.
I have seen how powerful this model can be when done right.
2. The smart city and government deployment model
Then there are cities.
Cities are different.
They already have many solutions. Parking. Flood sensors. Air quality. Lighting. Waste.
The problem is not a lack of data.
The problem is fragmentation.
Every system has its own dashboard. Its own vendor. Its own silo.
Local councils want a single platform, deployed on-premises, where everything comes together.
In some cases, councils cannot do this alone.
That is where state-level deployment makes sense.
One enterprise platform owned by the state.
Local councils connect their data.
Data stays within the country.
Visibility scales across regions.
It is pragmatic. It is cost-aware. It respects sovereignty.
This is bigger than one platform
As I reflect on this journey, I realise something.
The Enterprise IoT Platform is not just a product decision.
It is a philosophical stance.
It says:
You should own your data.
You should control your infrastructure.
You should not outsource accountability.
In a world rushing towards convenience, this is a reminder that responsibility still matters.
A quiet call to builders, cities, and leaders
If you are building systems that people depend on, ask yourself one simple question.
When things go wrong, who truly has control?
If the answer is unclear, it might be time to rethink how your platform is deployed.
I did.
And that rethink led us here.
I would love to hear your thoughts.
Where do you draw the line between convenience and control?
Share your reflections in the comments.